

How Google Search Works

Milliner’s Shop by August Macke

Most people, when they think of Google, think it’s a site where you…
Type something in
See results
Tada!
While this is all you need to know for practical use— there’s a lot more happening behind-the-scenes. In this article I will break down how a search engine works. At the end, I’ll share some alternatives to Google, including ChatGPT.
Invention of the World Wide Web
In 1989, Tim Berners-Lee at the European Organization for Nuclear Research (CERN) had a problem: The project was too large! There are too many files to keep track of.
So Tim devised a solution. A Document Management System to organize files. Normally, you’d follow a classification system, like books in a library or phone numbers in a directory — but Tim decided to try something else. He imagined a network of pages, connected via links (aka hypertext).
This organizational system became a set of interconnected pages, which looks like a Web, hence the term “Web”.

But then a problem arose. As the number of pages grew in size, the Web became increasingly harder to navigate. You couldn’t find what you were looking for; it became a library without a catalog.
Enter search engines. A search engine helps you find things on the Web. As Sergey Brin and Larry Page, founders of Google, said: we want to “Bring Order to the World Wide Web”.

The rest of the essay talks about how search engines work. In which there are three steps.
Find web pages
Store them in a database
Display results upon request
Search Engine = Web Crawler + Database + Display ResultsStep 1: Find Web Pages
All web pages are represented as HyperText Markup Language (HTML), which is a text format that describes the structure and contents of a page.
A search engine chooses a small subset of web pages, then follows the links on those pages to find new ones.
This process is known as crawling, or URL discovery.

More specifically, a crawler navigates to a URL and extracts its contents from the HTML — title, headers, images, text. It also renders JavaScript on the page because otherwise some of the HTML will be hidden.
Google’s crawler is known as GoogleBot, and they have two versions: Googlebot Desktop and Googlebot Mobile.
Step 2: Store Data

The next step is to store these web pages in a database. You also need to build an index (ie. storage layout) that makes it easy to search and retrieve.
To store web pages, Google uses Bigtable, a distributed NoSQL database. Distributed means it’s stored across many computers. NoSQL means it contains relatively unstructured data. Built in 2006, Google also uses Bigtable for Google Earth and Google Analytics.
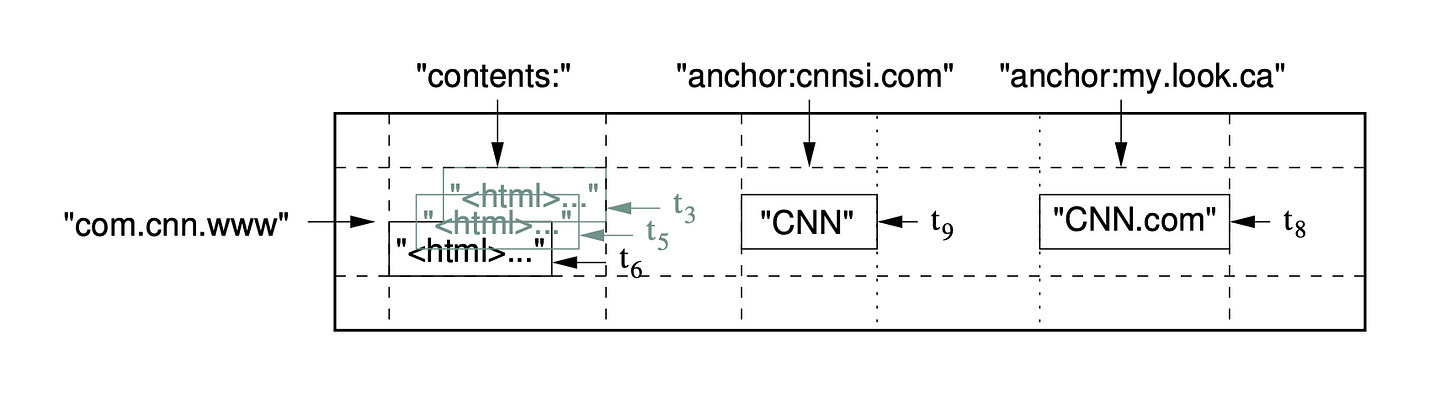
You want to store a couple things. The URL and contents of the page. You also want to store the timestamps, so you can keep track of when you indexed a page. Therefore, Google uses a 3-dimensional schema (see below). Rows are URLs, columns are contents, and each cell contains multiple timestamps.
In total, the Google Search index has hundreds of billions of web pages and is well over 100,000,000 gigabytes in size. In comparison, the text of all the books held in a small university might occupy only around 100 GB.

Step 3: Display Results
Lastly, you have to show people what they want to see. When you type something into Google Search, that word or phrase is known as a query. Google then searches its database for everything that matches the query and returns the results.
But let’s dive into the details for a bit. What about typos?

On a basic level, you can match the exact search term, and indeed, some tools do exactly this.
But you might want to take human error into account. After all, your job is to return the most relevant results, so it helps to have some wiggle room.
Introducing Approximate Search
In my algorithms class, I learned that Edit Distance is the minimum number of operations necessary to convert one word into another. Operations include adding, deleting, or replacing a letter.
For example, if you want to turn the word Monet into Manet, you could replace the letter o with the letter a. Since we only had to make one change, we say these two words have an Edit Distance of 1.

Modern search engines use approximate search. If your query is close enough, then it’ll show you the results anyway. This is why when you type in “aple”, you’ll see the results for “apple”.
Ok, now what about fetching results from the database?
With billions of web pages, your task is to show the 2-3 results that are most relevant. After all, nobody is scrolling to Page 2 of Google Search.

Here is where Google’s ingenuity comes in.
In 1998, Sergey Brin and Larry Page, proposed an algorithm for ranking web pages, called PageRank, that measures every page based on importance. Basically, the page with the most links, from other pages with the most links, is ranked the highest.

Nowadays, PageRank is one factor out of hundreds. Other factors include:
How old a web page is
How long your domain name is
How fast it takes to load a page
How “mobile-friendly” the page is
How hard the text is to read
And many more…
People spend entire careers studying these factors, usually with the goal to boost their site. This field of study is called Search Engine Optimization (SEO).
Limitations of Google
When you Google something, you’re not actually searching the web; you’re searching Google’s index of the web. Estimates show that Google only indexes 0.03% of the web. The other 99.97% is inaccessible from Google and is known as the Deep Web.
Reply in the comments if you want to know how to access the Deep Web!Google Search is great for certain queries, such as looking up a World Cup score, or following the local news, but not for others. Indeed, it’s terrible for a whole class of queries, such as “What should I write about?” or “What was that place we went to in 2013?” Google’s novelty bias also makes it hard to find old stuff.

Since many questions are ungoogleable, you’ll have to look elsewhere. Here’s an underrated search method. Look through your Contacts list and find a suitable person and then text them your question. The answer you get may be better than Google’s.
Beyond Google

Studies show that people are moving away from Google search. As more content is being published on other platforms (eg. YouTube, TikTok, Reddit, Github), site-specific search becomes more powerful. Teens use TikTok search to find recipes. Software engineers browse GitHub to find code. I use Spotify to find songs, Amazon to find books, WikiArt to find artworks, and Google Maps to find places to visit.
Are you interested in a Part 2 on “How to use search more effectively to find what you want?” Let me know by replying in the comments!
“Estimates show that Google only indexes 0.03% of the web. The other 99.97% is inaccessible from Google...” wow, what a startling statistic. Yes, teach me about accessing the deep web!
Well done Leo! Excited for more deep dives.